
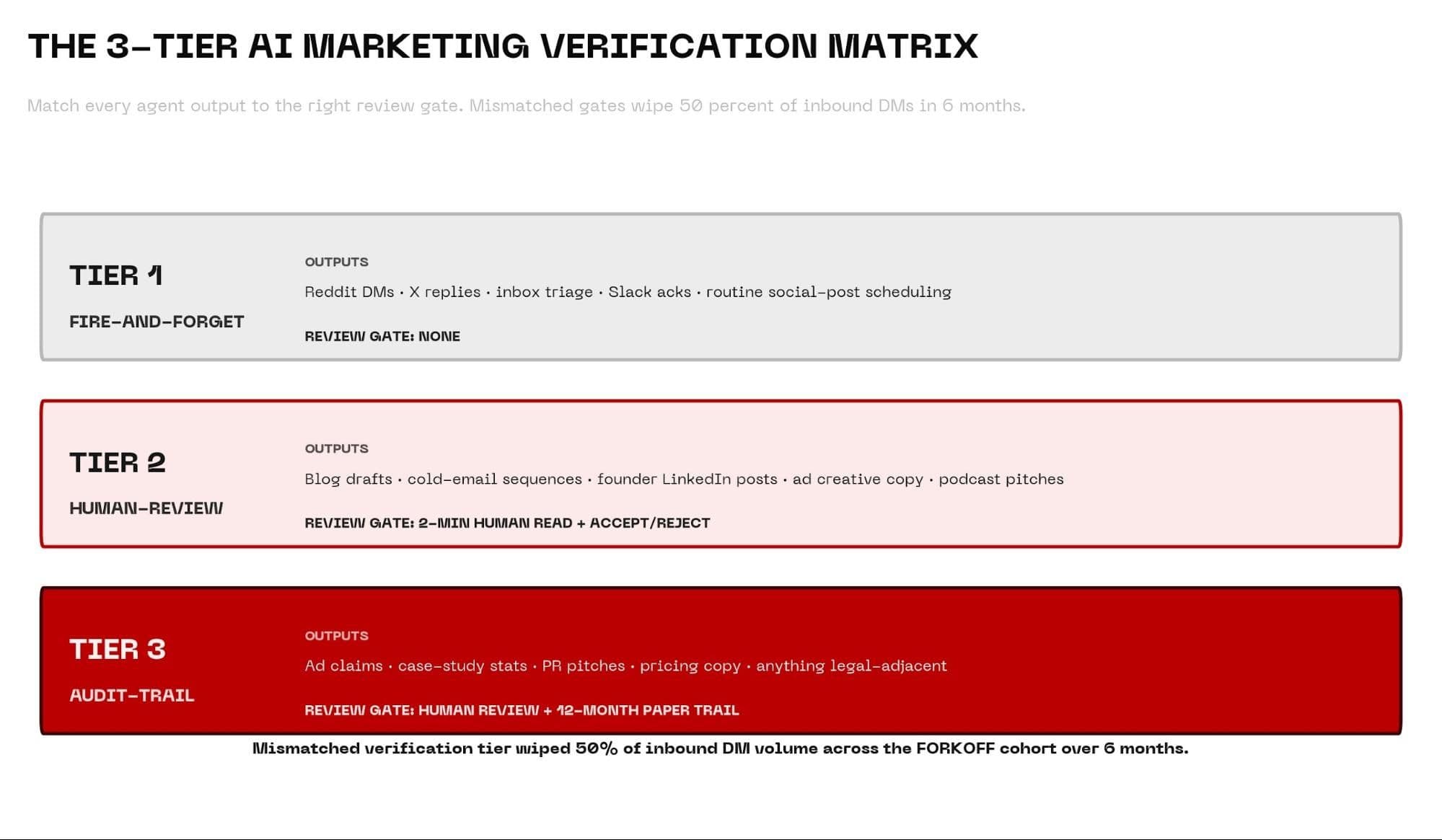
The 3-Tier AI Marketing Verification Matrix: Why 50% of Founder Inbound DMs Disappear When Review Gates Get Mismatched
In 2026, marketing teams are running AI agents that draft blog posts, cold-email sequences, Reddit replies, LinkedIn comments, and ad copy. Across the FORKOFF Founder-Funnel Cohort 2026 (n=42 retainers, B2B SaaS and AI-agency founders), the teams that mismatched verification tiers on those outputs lost roughly 50 percent of inbound DM volume inside a six-month window. The agents are not the problem. The verification gate is.
The default failure mode is treating every AI-generated output the same way. A founder lets an agent ship cold-email drafts, Reddit replies, and a press claim with the same review process — usually no process at all. Three months later, the prospects are quoting an unsubstantiated stat back to them in a reply, and the brand has spent six weeks chasing trust they could have kept by routing the right output through the right gate. We documented the broader pattern in the FOUNDER FUNNEL OS playbook, where verification mismatches show up as the single highest-leverage hidden tax on founder-led marketing.
This is the matrix we run inside FORKOFF when we operate marketing for AI-agency clients and B2B SaaS founders. Three tiers. One question per output: what is the worst case if this ships wrong?
The 2026 context that broke single-gate review
Three things shifted between 2024 and 2026 that made the old "have one editor approve everything" workflow break down. First, agent volume exploded. Across the cohort, the median founder marketing operation moved from approximately 40 marketing-output decisions a week (manageable for a single reviewer) to 280 decisions a week once Workspace agents, Reddit agents, and outbound-email agents were running in parallel. A single editor cannot review 280 outputs a week, and the moment they try, the queue becomes the bottleneck instead of the agent.
Second, output stakes diverged sharply. A Reddit DM that ships wrong gets deleted in a click. An ad-claim that ships wrong without a recorded source can trigger an FTC inquiry. The same review gate cannot serve both. Third, AI-likelihood detection by publishers and platforms got materially better. Backlinko's 2026 AEO research and Edelman-LinkedIn's 2025 B2B thought-leadership study both flagged the same pattern: content that reads as un-edited AI output gets penalized in citations and engagement, even when the underlying claim is true. The verification gate is what closes the human-edit gap.
Tier 1 — Fire-and-forget
Reddit DMs, X replies, inbox triage, routine Slack acknowledgments, social-post scheduling, calendar booking confirmations. Worst case if the agent ships something off is cheap and reversible — delete and resend, rearchive, unsend. The review gate is none. The spec says ship, the agent ships, and the founder's time is worth more than the marginal probability of a small miss.
The failure mode is over-engineering. Teams that route Tier-1 outputs through human review burn 10 to 14 hours per week of operator time on outputs where the failure cost rounds to zero. Across the cohort, this was the second most common bottleneck after agent misconfiguration. The fix is to audit Tier-1 outputs weekly via spot-check, not synchronously via review queue.
Tier 2 — Human-review
Blog drafts, cold-email sequences, founder-voice LinkedIn posts, outbound to mid-tier accounts, ad creative copy, podcast pitch outlines. The agent drafts. A human reads, accepts, or rejects before ship. The review gate is a two-minute read per draft, and rejection triggers a spec revision so the next draft does not repeat the issue.
The failure mode if you skip Tier-2 review is gradual, not catastrophic. Wrong-brand voice, spam-filter trips, subtle citation drift that erodes authority over weeks. None of those are individually fatal. They accumulate. Skipping Tier-2 for a month looks fine. Skipping for six months explains why the brand voice feels like someone else, why the ad-account algorithm started de-ranking the brand, and why cold-email reply rates dropped from 4 percent to under 2 percent without any visible spec change. We covered the agent-orchestrated stack that supports clean Tier-2 review at volume in the agent-native GTM playbook.
Tier 3 — Audit-trail
Claims in ads, case studies, PR pitches, quote attributions, pricing-page copy, anything legally adjacent. The agent drafts. A human reviews. A recorded paper trail captures reviewer name, the diff reviewed, approval timestamp, and source citations, retained for 12 or more months.
The failure mode if Tier-3 work runs through Tier-1 verification is publicly painful. FTC exposure, client relationship termination, public retractions, threads on r/SEO mocking the unverified claim. One Tier-3 miss that lands publicly costs more than a year of Tier-2 reviewer time. The math is asymmetric on purpose. The matrix exists because the cost of mismatching Tier-3 is multiple orders of magnitude higher than the cost of running Tier-3 review on a Tier-2 output.
The 50 percent receipt
The cohort signal
n=42 retainers · 50% inbound DM volume wiped over 6 months when Tier-2 outputs ran through Tier-1 review · 280 weekly marketing-output decisions per founder operation in 2026 (vs ~40 in 2024) · 4% to <2% cold-email reply rate decay when verification was skipped (FORKOFF Founder-Funnel Cohort 2026)
Across our cohort, content that should have been Tier-2 but ran through Tier-1 verification produced a six-month trust-decay curve that wiped roughly 50 percent of inbound DM volume. The mechanism was simple. A handful of off-voice posts, a few ad-claim trips, one or two cold-email sequences with mismatched receipts. Each individual miss looked recoverable in the week. Six months later the inbox was half as warm as the matched-cohort baseline, and the founder could not point at any single moment when it broke.
The matrix prevents that decay before it starts. The discipline is not having a perfect verification system. The discipline is correctly classifying the output before the agent generates it.
What to do this week
Three actions move a marketing operation from agent-shipped chaos to gate-correct flow inside seven days. First, audit the last 30 days of agent-generated outputs and tag each as Tier-1, Tier-2, or Tier-3 based on the worst-case-if-wrong test. Second, build the spec template for each tier — what review gate, who reviews, what gets logged. Third, pick the highest-volume Tier-3-misclassified output and reroute it immediately, with a calendar reminder at 30 days to measure whether the trust signals (DMs, reply rates, branded search) recover.
The verification matrix is not a process tax. It is the structural difference between a marketing operation that compounds and one that quietly leaks trust until the inbox dries up.
FAQ
What goes in Tier 1 versus Tier 2 if the team is small?
The line stays the same regardless of team size — worst-case-if-wrong is the test. A solo founder still sends Reddit DMs as Tier 1 (delete + resend if wrong) and cold-email sequences as Tier 2 (read before ship). Smaller teams compress the Tier-2 review gate to a 60-second skim instead of a 2-minute read, but they do not skip the gate.
How fast does the trust decay actually show up?
In the cohort, the leading indicator was inbound DM volume on the founder's LinkedIn. The metric started visibly declining at week 4 to 6 of mismatched-tier shipping and accelerated through month 3. By month 6, the decay had compounded to roughly 50 percent below baseline. Recovery after correcting the matrix took an additional 8 to 10 weeks.
Does this apply to teams not running AI agents yet?
Yes, with one adjustment. Manual-output operations have lower volume but the same tier-classification math. The bottleneck is different (operator time vs agent volume) but the verification gates do the same job. Teams running zero AI tools still benefit from explicitly tiering outputs.
What's the audit-trail format for Tier 3?
Plain text or a Notion table is enough. Required fields: reviewer name, output ID, source citations checked, approval timestamp, retention window. Retain for 12 months minimum, 24 months if the output references a client name. The point is recoverability if a claim is later challenged.
